This article desribes what api protection is and the different requirements and solution to implement it.1
Background
Oauth capabilities
The two main capabilities of the OAuth specifications are:
- Authentication: Dealing with users and authentication, while externalizing this complexity from applications
- Data Protection/Authorization: Design patterns that enable APIs to authorize access to resources based on tokens
API clients use different authentication flows (capability 1), but APIs always receive and evaluate an access tokens protect data (capability 2):
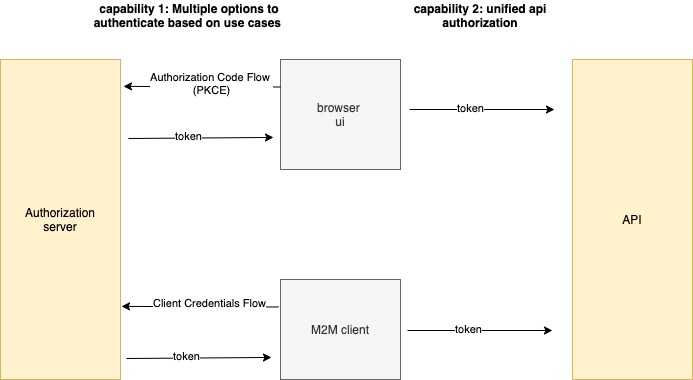
This post will focus on OAuth data protection/authorization (capability 2) and how it maps to complex business rules.
Apis and business rules
The request to get data from a UI includes a token with the subject claim. The API applies business rules to authorize requests:
 Examples for authorization business rules are:
Examples for authorization business rules are:
- User Bob has Write Access to orders for customers he manages
- User Bob has View Access to all orders for his own branch
- User Bob has No Access to orders for other branches
We will show how to manage these types of rule in an OAuth secured API.
Solution
You implement authorization in three phases:
- Token Validation: JWT Access Token Validation, to ensure integrity of the message credential
- Scope Checks: Sanity checks to ensure that an access token is allowed to be used for a particular business area
- Claims Based Authorization: Detailed permission checks against resources, using domain specific data
The main work happens in step 3.
Step 1: token validation
The token validation is the entry level check to authenticate the request to the API, after which the API can trust data in the access token’s payload. The token validate happens with standard crypographic libraries based on a public key cryptography.2 The API verifies the JWT’s digital signature and if the token is expired. If the token is not valid the API return a 401 error:
"code": "unauthorized",
"message": "Missing, invalid or expired access token"
Step 2: audience & scopes
Audience checks
In the API check the audience of received access tokens. The most common setup is for a set of related APIs to use the same audience. This enables JWT access tokens to be forwarded between microservices:
| API | Audience |
|---|---|
| Orders | api.mycompany.com |
| Customers | api.mycompany.com |
| Products | api.mycompany.com |
If you deal with different subdivisions of a large company, then it is usually recommended to use a different audience per subdivision.
In cases of delegated access: scope check
The authorization server includes scopes in the access tokens to represent an Area of Data and Permissions on that Data of the api. Use scopes only in cases that the user delegate access to a third party (e.g. user give the linkedin app read access to the contacts of his gmail account).3
| Example | Usage |
|---|---|
| orders | Indicates that an access token grants access to orders placed by a user |
| orders_read | Indicates that an access token cannot be used to make data changes to orders |
When the user delegates the access you should show a consent screen in the authorization server that displays scopes. The concent screen informs the the user which data they are granting access to, and whether they are granting read or write access.
Built-in scopes
OAuth/OpenID Connect uses built in scopes for Personally Identifiable Information (PII) stored by the Authorization Server:
| Examples | Usage Scenario |
|---|---|
| openid | Indicates that the user’s identity is being used, via the OpenID Connect protocol |
| profile | Indicates that the user’s name and possibly other information is being used |
Scope limitations
You define scopes fixed at design time and you cannot use them for dynamic purposes, such as different scopes for different types of user. Whenever you need to perform dynamic authorization, you must use claims.
Step 3: claims
For (role based) access control the API use custom claims. Note that none of this data is stored in the Authorization Server. For example:
| Claim | Represents |
|---|---|
| User ID | The user id with which transactions are stored in the domain specific data |
| User Role | Two user roles are involved, for a normal user and an administrative user |
| User Regions | An administrator grants users access to data for one or more regions, represented as an array |
The third of these is an array claim, to represent the type of authorization required in many real world business systems:
- A doctor might only see data for particular surgeries
- A coverage banker might only see data for particular industry sectors
- A retail worker might only see data for particular branches
Claims requirements
There are two main requirements when working with claims:
| Requirement | Description |
|---|---|
| API Data | The API must receive the data it needs in order to implement its domain specific authorization |
| Confidentiality | Access tokens returned to internet clients must not reveal all of this information |
Claims architecture option 1
The ideal way to meet the above requirements is for the Authorization Server to reach out to the API at the time of token issuance to get custom claims and then to include the custom claims in the access token. The Authorization Server stores this state, generates a confidential reference token format, which is typically a UUID or something similar and returns the access token to clients :
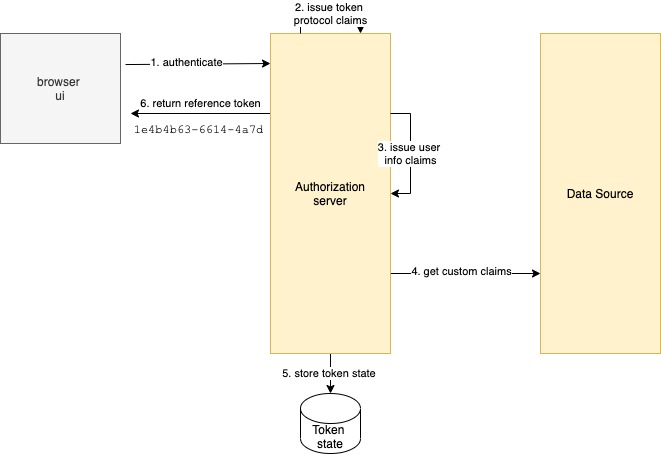
When a client calls the API, the reference token is introspected to get a JWT access token, which is then forwarded to the API. The introspection is usually done in an API gateway that is placed in front of the API:
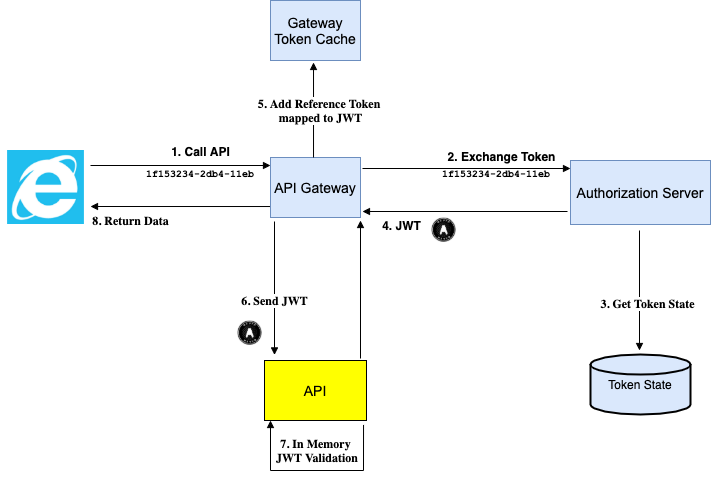 This is a great solution when supported, since all claims issued are audited by the Authorization Server and it scales very well if the JWT needs to be forwarded between microservices.
This is a great solution when supported, since all claims issued are audited by the Authorization Server and it scales very well if the JWT needs to be forwarded between microservices.
Claims architecture option 2
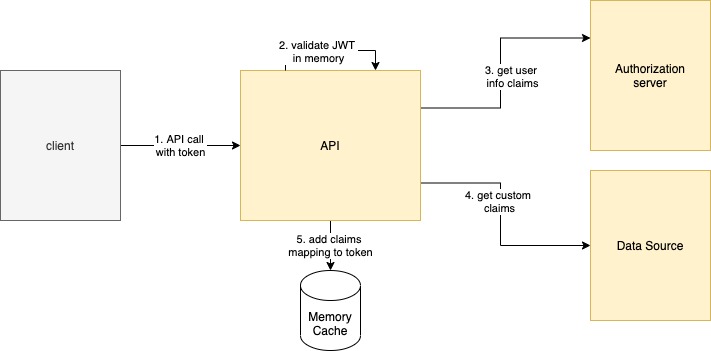
For specific (e.g. legacy) integration or if the authorization server doesn't support reaching out for custom claims you can implement the custome claim lookup in the API itself. The API looks up the custom claims when it first recieves an access token, and then caches it:

For all subsequent requests with the same access token the API quickly looks up the extra claims from the memory cache:
A sample JWT access token for the second option contains the following data. The access token is pretty confidential, so we are meeting that requirement:

Implemenation
Claims principal
First collec the APIs claims into a ClaimsPrincipal class. This should be designed early, to provide the information the API needs for authorization:

Authorizer class
When using the Option 2 architecture we will use an Authorizer class to perform the claims lookup, populate the Claims Principal, and to deal with caching results:

Claims caching behaviour
Our next code sample will include some logging to demonstrate the above pattern. This highlights how Claims Lookup is only done when a new access token is received, and is very fast on subsequent requests:

The claims cache has the following characteristics:
- Each cache entry will have a key equal to a hash of the access token, so that getting a new access token forces a new claims lookup
- The lifetime of the cache entry must never exceed the expiry time of the received access token, and we will use an upper limit of 30 minutes
This means that if a user’s permissions change, they can log off and log on again to get a new access token, after which their updated privileges will come into effect.
Business authorization
The claims principal, or its domain specific claims, can then be injected into business logic classes:

The API can then deny access if unauthorized resources are requested, or filter collections to only include authorized items:

Footnotes & resources
-
- https://www.thomasvitale.com/spring-security-keycloak/
- metadata endpoint
- https://github.com/keycloak/keycloak-documentation/blob/main/securing_apps/topics/oidc/oidc-generic.adoc
http://localhost:8443/realms/master/.well-known/openid-configuration
-
API Authorization Design – OAuth Architecture Guidance-1 - overall api authorization components ↩
-
JWT Access Token Validation – OAuth Architecture Guidance-1 ↩
-
On The Nature of OAuth2s Scopes Auth0-1 - describes why you should use scopes only in delegation scenarios ↩